

随着ChatGPT、GPT4、文心一言等大模型越来越被大家所关注。海天瑞声「优雅打工人ChatGPT」系列和大家聊聊ChatGPT的「优雅」。
ChatGPT是使用大规模的文本数据集进行训练的一个大语言模型(LLM)。其工作原理可以简单地概括为:输入文本的编码、文本生成的解码、以及通过用户反馈不断迭代的训练优化过程。
近几年,有不少在大量数据上训练的大语言模型,但这些模型都没有受到ChatGPT如此空前的关注度。主要原因在于 ChatGPT与人的交互过程更加拟人化,可以根据用户提问,给出符合用户预期的反馈。
这一功能之所以能够落地,得益于大语言模型生成领域的新训练范式:人类反馈强化学习 = RLHF (Reinforcement Learning from Human Feedback),即以强化学习方式依据人类反馈优化语言模型。
RLHF技术原理
那么什么是RLHF技术呢?还是先问问ChatGPT吧~

概括来说,人类反馈强化学习 (RLHF) 是一种训练大型语言模型的方法,通过不断接收人类评估员的反馈来提升对话生成能力。RLHF通过迭代更新模型参数,让语言模型逐步学习并改进其响应质量,以更好地满足用户需求和预期。
RLHF由多个训练阶段组成,并且会产生多个训练的模型。其主要步骤包括三个:
Step1:预训练一个大语言模型
首先,使用经典的语言模型预训练方法训练一个大语言模型。
然后,挑选人工标注或者根据上下文信息提示筛选出来的优质数据对该模型进行微调,得到第一阶段的大语言模型。
其中,微调的目的是为了让大语言模型更加鲁棒和适合对话场景,不至于被原始大数据中的脏数据、假数据污染,导致模型性能的降低。
在这里,微调使用的人工标注或筛选的数据质量尤为关键,对最终大语言模型的性能有重要的影响。
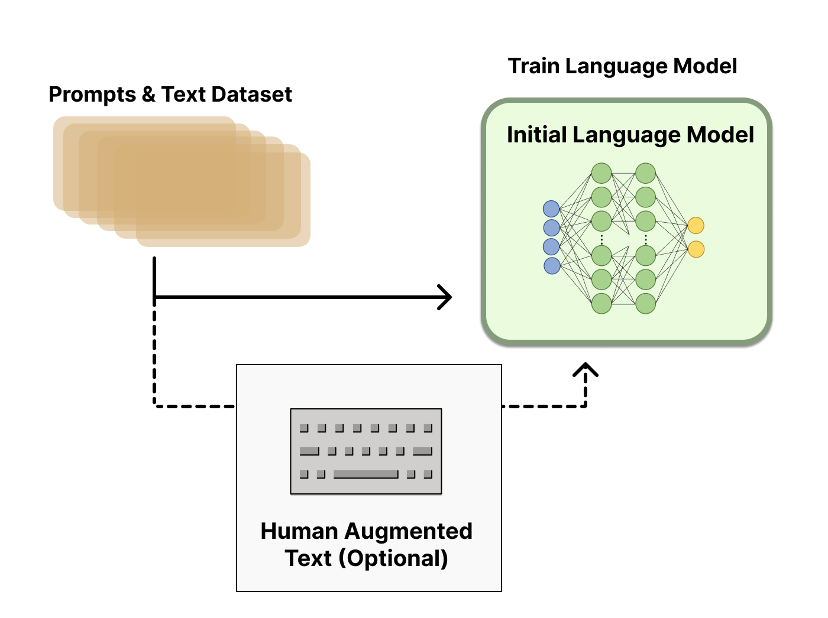
预训练一个大语言模型流程 (参考文献[1])
TIPS
在RLHF训练ChatGPT的第一个阶段,需要人工标注的数据对大语言模型进行微调,这是增强大语言模型性能的关键步骤。
同时也需要对训练数据进行清洗,防止无监督数据中的脏数据、非法数据对模型性能造成不良影响。
Step2:整合数据并训练奖励模型
RLHF在这个阶段使用人工标注的数据,训练一个奖励模型,该模型根据人类偏好进行校准 [2]。
该模型或系统的目标是接收一系列文本,并返回一个标量奖励,该奖励应在数字上代表人类偏好。
该系统既可以是端到端的语言模型,也可以是模块化系统 [4] 。
在RLHF的后续阶段中,该输出将作为标量奖励与现有的强化学习RL算法进行无缝集成,因此至关重要。
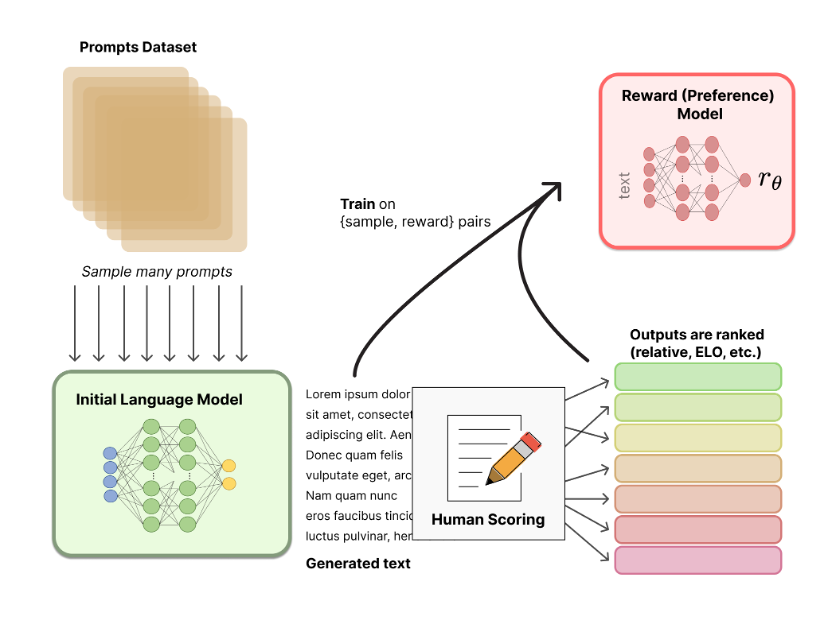
奖励模型训练 (参考文献[1])
TIPS
在这个阶段,更加需要人工标注的偏好信息予以模型正确的反馈,通过反馈给模型输出打分,从而支持训练一个能够产生符合人类预期答案的奖励模型。
这个阶段的人工标注不再是简单的Label标注,更多是要基于大语言模型的训练原理和与用户的交互方式,给出正确的 和答案打分,才能更好地引导后续模型在微调时输出更正确合理的答案。
这也使得对标注人员的素质提出了更高的要求,不具备相应背景的标注人员,很难高质量完成相应的标注工作。
Step3:强化学习策略微调语言模型
强化训练语言模型的优化策略包括梯度强化学习算法、近端策略优化微调初始语言模型的部分或全部参数 [3]。
该策略是一种语言模型,它接受提示并返回一系列文本 (或只是文本的概率分布)。
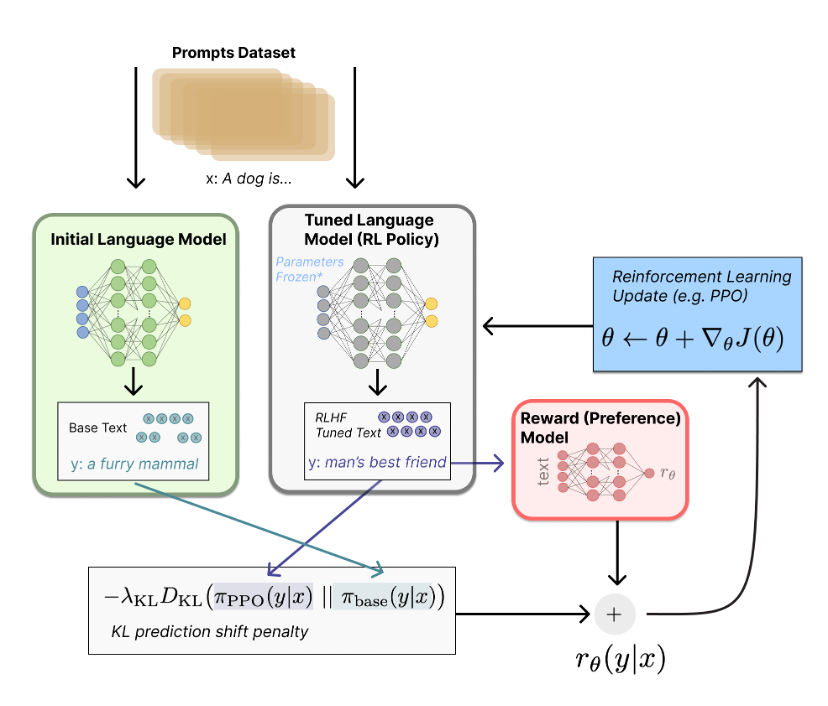
强化学习 (参考文献[1])
数据:大模型高质量输出的关键
随着人工智能进入大模型时代,数据需求和数据服务模式不断提升,数据的质量以及数据清洗的工程化能力将会显著拉开大模型预训练阶段的效果差距;同时,更多模型或将采用类强化学习模式,来进行特定领域或特定方向上的优化迭代,以使得机器能够以更加接近于人类期望的方式提供答案输出。
对于大模型训练而言,不仅需要持续获取 大规模、高质量、多模态、多场景、多垂向的数据,更须具备 持续迭代的高质量数据清洗和标注策略,以不断提升包括预训练、模型微调及奖励模型等过程中所需数据的质量,确保语言类和常识性知识之外的其他垂直领域的应用场景的能力提升,为大模型的精确性、通用性及泛化能力的实现奠定坚实基础。
参考文献:
[1] Lambert, et al., "Illustrating Reinforcement Learning from Human Feedback (RLHF)", Hugging Face Blog, 2022.
[2] Fine-Tuning Language Models from Human Preferences (Zieglar et al. 2019): An early paper that studies the impact of reward learning on four specific tasks.
[3] Learning to summarize with human feedback (Stiennon et al., 2020): RLHF applied to the task of summarizing text. Also, Recursively Summarizing Books with Human Feedback (OpenAI Alignment Team 2021), follow on work summarizing books.
[4] WebGPT: Browser-assisted question-answering with human feedback (OpenAI, 2021): Using RLHF to train an agent to navigate the web.
